Abstract
Comparatively, model ensembling generally provides more stable and superior performance that aggregates multiple models by averaging outputs. However, it incurs higher inference costs and increased storage requirements. While previous studies experimentally showed the similarities between model merging and ensembling, theoretical evidence and evaluation metrics remain lacking. To address this gap, we introduce Merging-ensembling loss (M-Loss), a novel evaluation metric that quantifies the compatibility of merging source models using very limited unlabeled data. By measuring the discrepancy between parameter averaging and model ensembling at layer and node levels, M-Loss facilitates more effective merging strategies. Specifically, M-Loss serves both as a quantitative criterion of the theoretical feasibility of model merging, and a guide for parameter significance in model pruning. Our theoretical analysis and empirical evaluations demonstrate that incorporating M-Loss into the merging process significantly improves the alignment between merged models and model ensembling, providing a scalable and efficient framework for accurate model consolidation. Our codes are available in https://github.com/languangduan/mLoss.
Background
Training of large-scale models is both computationally intensive and often constrained by the availability of labeled data. Model merging offers a compelling alternative by directly integrating the weights of multiple source models without requiring additional data or extensive training. However, conventional model merging techniques, such as parameter averaging, often suffer from the unintended combination of non-generalizable features, especially when source models exhibit significant weight disparities.
Comparatively, model ensembling generally provides more stable and superior performance by averaging outputs, but it incurs higher inference costs and increased storage requirements. While previous studies experimentally showed the similarities between model merging and ensembling, theoretical evidence and evaluation metrics remain lacking.
The discrepancy between model merging and ensembling arises mainly from non-linear activations. We examine the flow of intermediate representations around activations and identify linearly correlated model parameters (LCP): parameter subsets that jointly influence a node’s representation in a row-wise manner, motivating layer-/node-level measurements and row-wise operations.
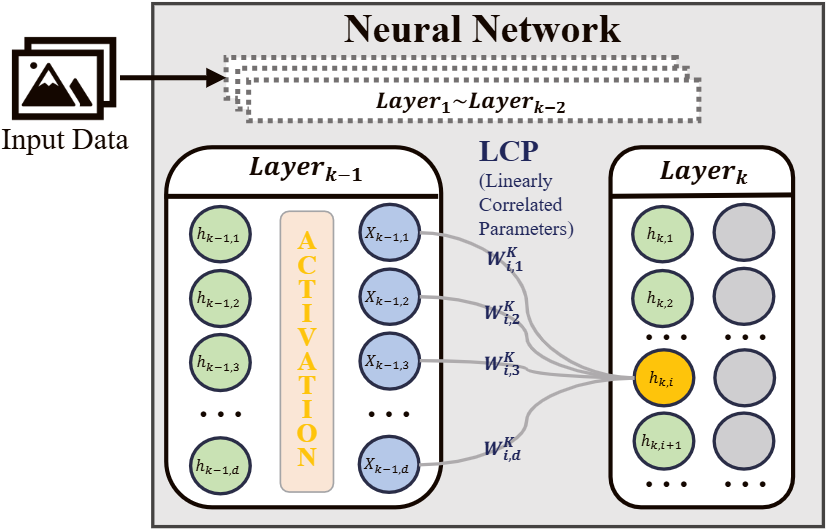
Visualization of Linearly Correlated Parameters (LCP) in a neural network .
To address this gap, we introduce Merging-ensembling loss (M-Loss), a metric that quantifies the compatibility of merging source models using very limited unlabeled data by measuring the discrepancy between parameter averaging and model ensembling at layer and node levels. M-Loss serves as both a quantitative criterion for the theoretical feasibility of model merging and a guide for parameter significance in pruning.
Problem Statement
In large-scale deep learning, reliance on large labeled datasets and intensive computation limits supervised methods. Model merging fuses the weights of multiple pretrained or fine-tuned models into a single network to reduce data collection and training costs, but simple parameter averaging can combine non-generalizable features and fails when source models exhibit significant weight disparities. Existing research lacks a theoretical tool to assess model merging compatibility without labeled data.
The goal is to evaluate and guide model merging using only limited unlabeled data, meeting two key requirements:
- Compatibility Assessment: Quantify the discrepancy between parameter averaging (merged model) and model ensembling (averaged outputs) to assess mergeability without labeled test sets.
- Practical Guidance: Provide layer-/node-level signals to guide merging strategies (e.g., pruning schedules and hyperparameter selection) and improve alignment with ensembling.
Because simple parameter averaging often fails under non-linear architectures and weight disparities, a principled evaluation metric and merge-guided mechanism are necessary.
Methodology
The proposed framework, M-Loss for Mergeability and Merge-Guided Pruning, addresses model merging with limited unlabeled data in three main steps:
- Merging–Ensembling Discrepancy Measurement (M-Loss)
- Given a small unlabeled set, compute the layer-/node-level discrepancy between parameter averaging (merged model) and output averaging (ensemble).
- Produce an M-Loss score map that quantifies mergeability without labels and highlights node-level conflicts.
- Theoretical analysis under common activations (ReLU, GELU, Leaky ReLU) explains when fine-tuned models from a shared backbone can be effectively merged.
- LCP-Informed Perspective for Structure
- Analyze intermediate representations around non-linear activations to identify linearly correlated model parameters (LCP), i.e., row-wise parameter groups that jointly influence a node’s representation.
- Use this perspective to align the granularity of measurement (node-level) with the granularity of intervention (row-wise operations).
- Merge-Guided Pruning and Integration (M-TIES)
- Convert node-wise M-Loss scores into dynamic row-wise keep rates to prioritize low-conflict parameters.
- Plug these keep rates into standard merging backends (e.g., TIES, DARE) to perform pruning/scheduling and parameter fusion.
- Resulting merged models better align with ensembling performance while reducing inference and storage overhead.
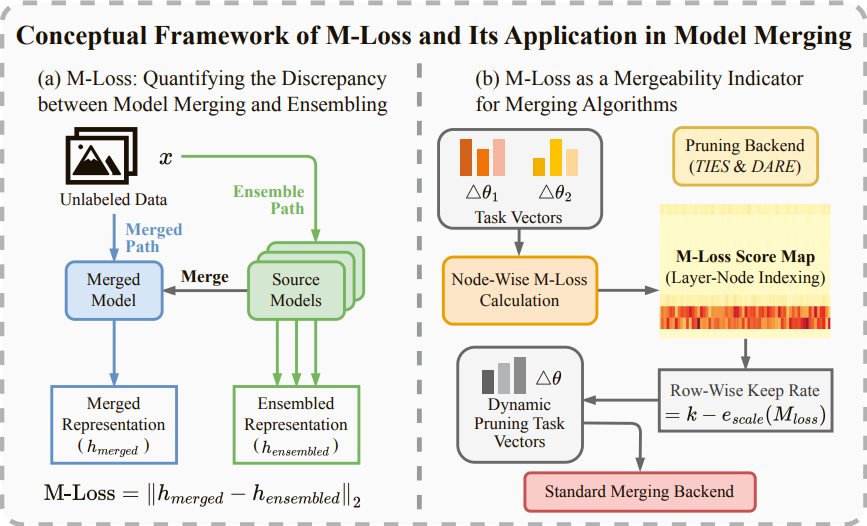
Conceptual overview of M-Loss and its use in M-TIES. (a) M-Loss measures the discrepancy between parameter-averaged and ensembled representations on unlabeled data, producing layer-/node-wise scores. (b) The node-wise M-Loss score map drives dynamic row-wise keep rates, which integrate with standard merging backends (e.g., TIES Top-K or DARE) to improve mergeability and efficiency.
Experiments
Experimental Setup
To validate the effectiveness of the M-TIES method, we established the following experimental setup:
- Models:
- Vision Transformer (ViT-B/32, ViT-L/14), based on pretrained weights from OpenAI CLIP.
- Source Models:
- We fine-tuned the pretrained ViT on 8 different datasets to obtain the source models. These datasets include: RESISC45, Cars, MNIST, DTD, EuroSAT, GTSRB, SUN397, and SVHN.
- Baselines:
- We compared M-TIES with four mainstream merging methods:
- Simple Average
- Task Arithmetic
- TIES-Merging
- DARE
- We compared M-TIES with four mainstream merging methods:
- M-Loss Configuration:
- We used only 128 unlabeled samples to calculate M-Loss, which averages to just 16 samples per source dataset, making it highly practical for real-world scenarios.
- For non-linear layers (like Attention and MLP), we adopted the standard pruning strategy from TIES, as calculating M-Loss for these layers is more complex and prior research indicates they are less critical for merging.
- Hardware:
- All experiments were conducted on a single NVIDIA RTX A6000 GPU.
Experimental Results & Analysis
Main Performance
Our core experimental results, presented in the table below, demonstrate that M-TIES is the top-performing merging method on average for both ViT-B/32 and the larger ViT-L/14 backbones.
Specifically, on ViT-B/32, M-TIES achieves the highest average accuracy (73.23%) among all merging baselines. On the larger ViT-L/14 model, the advantage of M-TIES becomes even more pronounced. Its average accuracy of 85.28% not only surpasses other merging techniques but also comes remarkably close to the computationally expensive Ensemble baseline (85.56%). Notably, for ViT-L/14, M-TIES even outperforms the Ensemble method on 5 out of 8 individual tasks (RESISC45, MNIST, DTD, SUN397, and SVHN), validating our motivation to bridge the gap between model merging and ensembling.
Furthermore, M-TIES demonstrates better stability. On ViT-B/32, the accuracy variance of M-TIES across different tasks (172.22) is lower than that of TIES (203.27) and DARE (197.61), indicating that our method performs more consistently and does not disproportionately favor high-accuracy tasks.
Table 1: Accuracy comparison of merging methods on ViT-B/32 and ViT-L/14 backbones.
| Backbone | Method | RESISC45 | Cars | MNIST | DTD | EuroSAT | GTSRB | SUN397 | SVHN | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| ViT-B/32 | M-TIES | 72.60 | 61.07 | 97.62 | 54.84 | 82.02 | 72.44 | 62.19 | 83.06 | 73.23 |
| TIES | 70.67 | 58.61 | 98.30 | 54.20 | 80.22 | 72.11 | 59.01 | 86.20 | 72.42 | |
| Task Arithmetic | 71.27 | 60.70 | 95.32 | 51.76 | 79.74 | 67.32 | 62.06 | 76.68 | 70.61 | |
| Simple Avg. | 71.46 | 63.34 | 87.46 | 50.11 | 73.00 | 52.79 | 64.91 | 64.16 | 65.90 | |
| DARE | 69.97 | 57.98 | 97.95 | 53.24 | 78.89 | 72.00 | 59.14 | 83.96 | 71.64 | |
| Ensemble | 79.87 | 66.60 | 95.80 | 58.30 | 98.30 | 81.11 | 66.35 | 82.15 | 78.56 | |
| ViT-L/14 | M-TIES | 88.57 | 83.35 | 99.06 | 66.91 | 94.61 | 83.80 | 76.13 | 89.78 | 85.28 |
| TIES | 88.19 | 82.81 | 99.01 | 66.70 | 94.37 | 83.36 | 75.65 | 89.42 | 84.94 | |
| Task Arithmetic | 86.17 | 82.44 | 98.54 | 65.59 | 93.93 | 83.47 | 73.56 | 85.26 | 83.62 | |
| Simple Avg. | 82.67 | 81.54 | 97.01 | 62.77 | 91.17 | 70.63 | 71.65 | 78.23 | 79.46 | |
| DARE | 88.33 | 83.35 | 98.97 | 66.86 | 94.06 | 84.20 | 75.37 | 89.19 | 85.04 | |
| Ensemble | 87.73 | 85.36 | 98.78 | 66.81 | 98.24 | 87.92 | 74.76 | 84.92 | 85.56 |
Ablation Study: Which Layers to Prune?
We investigated the effect of applying the M-Loss guided pruning strategy to only a subset of the model’s layers. As shown in the tables below, applying M-Loss to only the last few layers of the ViT (e.g., layers 8, 9, and 10 for ViT-B/32) yields an average accuracy that is nearly identical to applying it to all layers. This confirms the findings of previous research: the deeper parts of a model are more critical for merging.
Table 2: Accuracy of M-TIES on ViT-B/32 with different layers pruned by M-Loss
| Layer Index | RESISC45 | Cars | MNIST | DTD | EuroSAT | GTSRB | SUN397 | SVHN | Avg |
|---|---|---|---|---|---|---|---|---|---|
| All | 72.603 | 61.074 | 97.620 | 54.840 | 82.019 | 72.439 | 62.195 | 83.063 | 73.232 |
| 0,8,9,10 | 72.619 | 61.112 | 97.570 | 55.000 | 82.000 | 72.328 | 62.337 | 82.760 | 73.216 |
| 8,9,10 | 72.619 | 61.099 | 97.560 | 55.000 | 82.074 | 72.312 | 62.333 | 82.771 | 73.221 |
Table 3: Accuracy of M-TIES on ViT-L/14 with different layers pruned by M-Loss
| Layer Index | RESISC45 | Cars | MNIST | DTD | EuroSAT | GTSRB | SUN397 | SVHN | Avg |
|---|---|---|---|---|---|---|---|---|---|
| All | 88.571 | 83.348 | 99.060 | 66.915 | 94.611 | 83.800 | 76.134 | 89.782 | 85.278 |
| 0, 20, 21, 22 | 88.587 | 83.273 | 99.070 | 66.809 | 94.593 | 83.903 | 76.088 | 89.747 | 85.259 |
| 20, 21, 22 | 88.571 | 83.273 | 99.070 | 66.809 | 94.611 | 83.895 | 76.065 | 89.751 | 85.256 |
Visualizing M-Loss
To intuitively understand the conflicts between models, we plotted a heatmap of the M-Loss distribution across different layers and node groups in ViT-B/32. As shown below, areas of high M-Loss (representing high conflict) are not uniformly distributed but are concentrated in specific layers and nodes. This finding strongly justifies that adopting a dynamic, node-level pruning strategy (like M-TIES) is more reasonable than a fixed, global pruning strategy (like TIES).
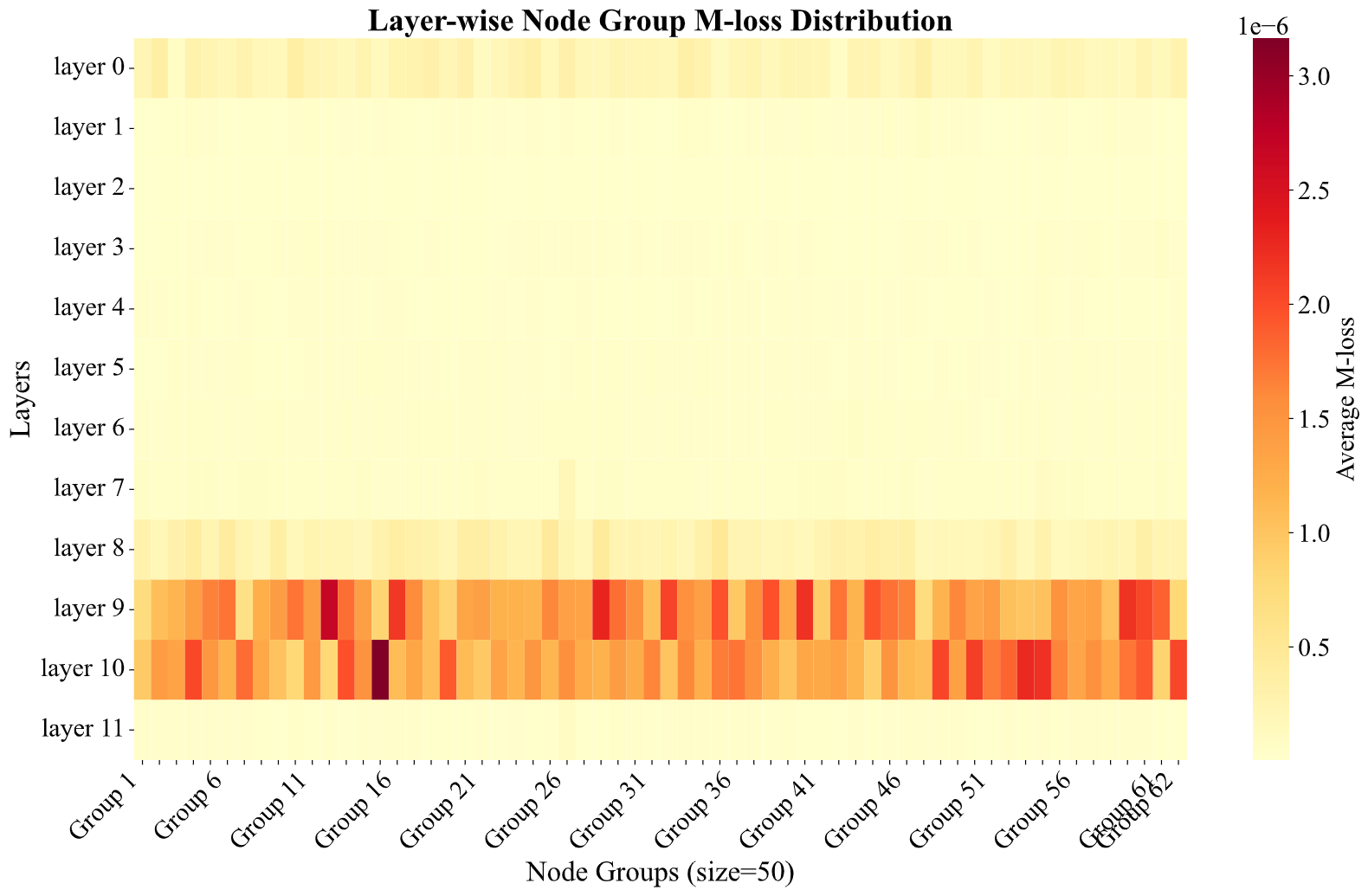 Layer-wise and node-group M-Loss distribution heatmap for ViT-B/32 models. Each colored block represents the average M-Loss of 50 consecutive nodes.
Layer-wise and node-group M-Loss distribution heatmap for ViT-B/32 models. Each colored block represents the average M-Loss of 50 consecutive nodes.
Computational Cost
M-TIES does not introduce significant time overhead.
- Theoretically, when calculating M-Loss for layer
k, the weights of the previousk-1layers have already been merged. Therefore, the input only needs to pass through the shared network once, greatly reducing the number of forward passes. - In practice, for the ViT-B/32 model, TIES merging takes about 30 seconds, while M-TIES takes 1 minute and 30 seconds. For the larger ViT-L/14, TIES takes 1 minute, and M-TIES takes 3 minutes. The additional time is mainly for the forward inference needed to calculate M-Loss, which is a negligible overhead compared to the entire evaluation process (5-15 minutes).
Conclusion and Future Work
Conclusion
This paper introduces M-Loss, a novel metric that quantifies the gap between parameter-averaged and output-averaged models without relying on labeled data. By computing the expected M-Loss for common activation functions, we provide theoretical justification for the conditions where parameter averaging yields predictions close to model ensembling, thereby establishing theoretical model merging feasibility. To show that M-Loss can be integrated with a concrete merging method, we integrate the M-Loss dynamic budget scheduler into the TIES merging framework, guiding the selective removal of conflicting parameters. The integration leads to superior performance compared to existing methods. Empirical evaluation results on ViT models underscore M-Loss’s effectiveness in identifying crucial parameters. Overall, this work advances the theoretical foundations of model merging and contributes practical tools for the efficient merging of multiple models.
Future Work
Building on this work, future research could explore several promising directions:
- Expanding Architectural Scope: Applying and adapting the M-Loss framework to other prominent architectures, particularly Large Language Models (LLMs), where model merging is of great interest.
- M-Loss for Non-Linear Layers: Developing efficient methods to compute M-Loss for more complex, non-linear layers (e.g., attention mechanisms) to enable a fully M-Loss-guided merging process.
- Beyond Pruning: Investigating the use of M-Loss to guide other aspects of the merging process, such as determining optimal model weighting schemes instead of simple uniform averaging.
- Broader Theoretical Analysis: Extending the theoretical analysis to cover a wider range of activation functions and network non-linearities.
Citation
@inproceedings{wang2025mloss,
title = {M-Loss: Quantifying Model Merging Compatibility with Limited Unlabeled Data},
author = {Wang, Tiantong and Duan, Yiyang and Chen, Haoyu and Wu, Tiantong and Lim, Wei Yang Bryan},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},
year = {2025},
publisher = {AAAI Press},
address = {Palo Alto, California, USA},
url = {https://openreview.net/forum?id=eJz0fKa8xg},
note = {To appear},
keywords = {model merging, parameter averaging, M-Loss, ViT, multimodel integration}
}